
MongoDBにちょっと興味があったのでMongoDBイン・アクションを買って読んでます
この本でTwitterからツイートをためて出力する例があるですが
この本rubyで例題が書かれてるんです..
まえがきに例題はrubyで示しますが基本的な機能しか使わないので他の言語でもできるでしょうと書いてあるんだけどSinatraモジュールさらっと使っててえっ!!てなった
PHPで作っても面白くないな〜と思ったのでPythonの勉強も兼ねてPythonでその例題を書いてみました
使用したもの
- MongoDB 2.4.9
- Python2.7.5
- pymongo
- twitter 1.10.2
- Juno 0.1.2
- jinja2 2.7.2
MongoDBはHomebrewで, モジュールはpipでインストールしました。
ファイル構成
. ├── config.py ├── templates │ └── index.html ├── twitterArchiver.py ├── update.py └── viewer.py
まずは設定ファイルを作成します
ここではMongoDBのDB設定とTwitter APIのkeyを設定します.
TwitterAPIのKEYはあらかじめ取得しておいてください
そういえばですがPythonには定数の定義なないのですね
→なぜPythonには”標準”で定数を定義できないのか?
・config.py
# Connection MongoDB info DATABASE_NAME = "twitter-archive" COLLECTION_NAME = "tweets" TAGS = ["mongodb", "python"] # Twitter key CONSUMER_KEY = '' CONSUMER_SECRET = '' OAUTH_TOKEN = '' OAUTH_TOKEN_SECRET = ''
次にTwitterからTweetを取得してMongoDBに保存するTwitterArchiverクラスを作成します
・twitterArchiver.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from config import *
from twitter import *
from pymongo import Connection
class TwitterArchiver:
def __init__(self, tag):
# DB接続設定
connection = Connection('localhost', 27017)
self.db = connection[DATABASE_NAME]
self.tweets = self.db[COLLECTION_NAME]
#indexを作成
self.tweets.create_index([('id', 1)], unique=True )
self.tweets.create_index([('tags',1), ('id', -1)] ) #複合index
#
self.tag = tag
self.tweets_found = 0
def update(self):
print "Starting Twitter search for " + self.tag
self.save_tweets_for(self.tag)
print self.tag + " %d tweet found " % self.tweets_found
def save_tweets_for(self, term):
t = Twitter(
auth=OAuth(
OAUTH_TOKEN, OAUTH_TOKEN_SECRET,
CONSUMER_KEY, CONSUMER_SECRET,
)
)
tweets = t.search.tweets( q=term, lang='ja', f='realtime')
for tweet in tweets['statuses']:
self.tweets_found += 1
# 検索ダグの挿入
tweet.update({'tags':term})
# tweetの保存
self.tweets.save(tweet)
実行はupdate.pyを作って実行します
・update.py
from twitterArchiver import *
from config import *
for tag in TAGS:
print tag
archive = TwitterArchiver(tag)
archive.update()
保存したTweetを確認するようにビューワーを作成
・viewer.py
# -*- coding: utf-8 -*-
from juno import *
from config import *
from pymongo import Connection
# DB接続設定
connection = Connection('localhost', 27017)
db = connection[DATABASE_NAME]
tweets = db[COLLECTION_NAME]
@route('/')
def index(web):
template("index.html",{"tweets":tweets.find()})
run()
Junoという軽量なフレームワークを用いています
テンプレートエンジンはjinja2を使用しています
・./templates/index.html
My Webpage</pre>
<style><!--
body {
background-color: #DBD4C2;
width: 1000px;
margin:50px auto;
}
h2 {
margin-top: 2em;
}
--></style>
<pre></pre>
<h1>Tweet Archive</h1>
<pre> {% for tweet in tweets %}</pre>
<h2>{{ tweet.text }}</h2>
<pre><a href="http://twitter.com/{{ tweet.user.screen_name }}">{{ tweet.user.screen_name }}</a> on {{ tweet.created_at }}
{% endfor %}
実行してみる
先程作成したupdate.pyを実行します。
$ python update.py mongodb Starting Twitter search for mongodb mongodb 15 tweet found python Starting Twitter search for python python 15 tweet found
次にServerを立ち上げます.
viewer.pyを実行します.
$ python viewer.py running Juno development server, to exit... connect to 127.0.0.1:8000 to use your app...
起動したら「127.0.0.1:8000」へアクセスして取得したTweetを確認.
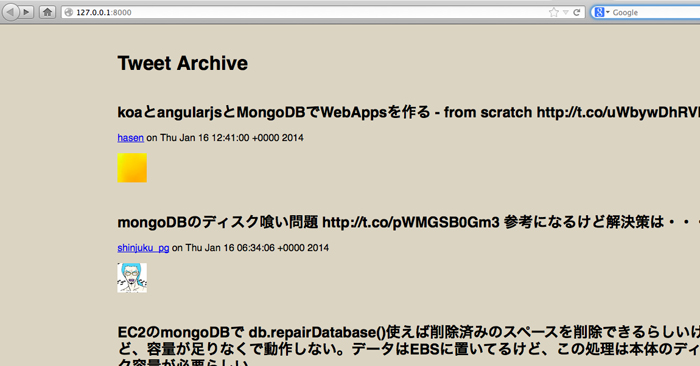 こんな感じに出力されます
こんな感じに出力されます
最後に
なにげにPythonちゃんと触るの初めてなので結構苦戦しました..
Pythonって謎インデントエラーが出て結構シビアだなと思った..
ただJunoやjinja2とかすごく使いやすかったです.本格的にPython勉強しようかなと思いました.